Data registration
Overview
Teaching: 20 min
Exercises: 20 minQuestions
What is data registration?
Why should you upload your data to a data repository?
What types of data repositories are there?
How to choose the right repository for your dataset?
Objectives
Describe why indexed data repositories are important
Summarise resources enabling you to choose a searchable repository
Data registration and the FAIR Principles
Data registration relates to the following 3 FAIR Principles (Table 3.1).
We will discuss and signpost these in this Episode.
| The FAIR Guiding Principles | |
|---|---|
| To be Findable: | F1. (meta)data are assigned a globally unique and persistent identifier F2. data are described with rich metadata (defined by R1 below) F3. metadata clearly and explicitly include the identifier of the data it describes F4. (meta)data are registered or indexed in a searchable resource |
| To be Accessible: | A1. (meta)data are retrievable by their identifier using a standardized communications protocol A1.1 the protocol is open, free, and universally implementable A1.2 the protocol allows for an authentication and authorization procedure, where necessary A2. metadata are accessible, even when the data are no longer available |
| To be Interoperable: | I1. (meta)data use a formal, accessible, shared, and broadly applicable language for knowledge representation. I2. (meta)data use vocabularies that follow FAIR principles I3. (meta)data include qualified references to other (meta)data |
| To be Reusable: | R1. meta(data) are richly described with a plurality of accurate and relevant attributes R1.1. (meta)data are released with a clear and accessible data usage license R1.2. (meta)data are associated with detailed provenance R1.3. (meta)data meet domain-relevant community standards |
Table 3.1: The 15 FAIR Guiding Principles. Principles relating to data registration in black.
What is data deposition and registration?
Data deposition and registration refer to the process of uploading data to a searchable resource, and providing appropriate metadata to facilitate its discoverability. For example, a data repository, where data and metadata can be uploaded, may enable it to be discovered, preserved and accessed. Here we use the general term data repository to describe any online storage location that can host deposited (meta)data.
In the context of FAIR, data deposition relates to a number of the Guiding Principles. Firstly, “(meta)data are registered or indexed in a searchable resource” (FAIR Principle F4). Searchable (indexed) metadata enables humans and computers to query and discover data of interest, though this depends on what is indexed. Here, indexing refers to a process that occurs within the architecture of the data repository (local indexing) where metadata are organised so that they can be queried based on a defined field. It is worth noting that community resources, focused on a particular domain (for example, the human database in Ensembl) are better indexed for a particular community, rather than generic repositories (for example, Zenodo) which may not index the community specific components, and may focus on higher level metadata. Indexing by an internet search engine is another example of this. Google (and other search engines, such as yahoo and yandex) have an agreed vocabulary (schema.org), within web pages, that are ‘scraped’ and indexed. While the focus of this vocabulary was originally intended for commercial products, community specific efforts to facilitate discipline-specific indexing are under way (for example, Bioschemas).
Why should I upload my data to a data repository?
Data repositories are generally preferred to file storage systems (such as Dropbox) or sharing data on an ad hoc basis, since they often better support FAIR best practice. Repositories will assign citable, “globally unique and persistent identifiers” (FAIR Principle F1) to data, and in some cases enable a data submitter to apply a data usage licence through association with the resource (FAIR Principle R1.1).
Although not exclusively, data repositories support the creation of metadata through curation interfaces providing drop-downs and text fields for metadata entry and validation. Often in the case of a domain or data-specific data repository, such as BioStudies shown in the previous Episode, drop-downs for metadata curation will link community-endorsed vocabularies (FAIR Principle R1.3).
Types of data repository
General public data repositories, such as Zenodo, are multidisciplinary and permit registration and upload of open and closed access (meta)data. Metadata curation is relatively high level and made searchable via indexing. Relating to data in the Life Sciences, Zenodo is often used to publish and provide citable URLs to supplementary data within articles, usually in instances where a domain repository does not exist.
Institutional repositories work similarly and provide an online archive for hosting, indexing and preserving research output specific to an institution. Typically these house more than data, providing a repository often for documents and articles. Institutions will have their own systems supported locally or buy into company solutions.
Discipline-specific repositories cater for communities and datatypes, and typically provide web interfaces to annotate rich metadata at the point when data are submitted. Examples of these belong to the suite of data repositories at the European Bioinformatics Institute (EBI) where rich metadata creation is supported by teams of curators.
Exercise
An example of a discipline specific repository is ArrayExpress database. ArrayExpress stores data from high-through functional genomics assays, such as RNAseq, ChIPseq and expression microarrays. The data submission interface of ArrayExpress is called Annotare. Without creating a login, what help is given to a person looking to submit a dataset for the first time?
Solution
Both a submission guide and YouTube video is provided.
Exercise
Finding more help on how to upload data to specific repositories The FAIR Cookbook is an online open resource housing specific ‘how to’ guides or recipes. Use the FAIR Cookbook to find two recipes for “depositing data to Zenodo” and “registering datasets with Wikidata”, respectively.
Solution
Open the Findability pulldown on the left hand banner to find recipes for the following: Depositing to generic repositories - Zenodo use case and Registering Datasets in Wikidata.
Exercise
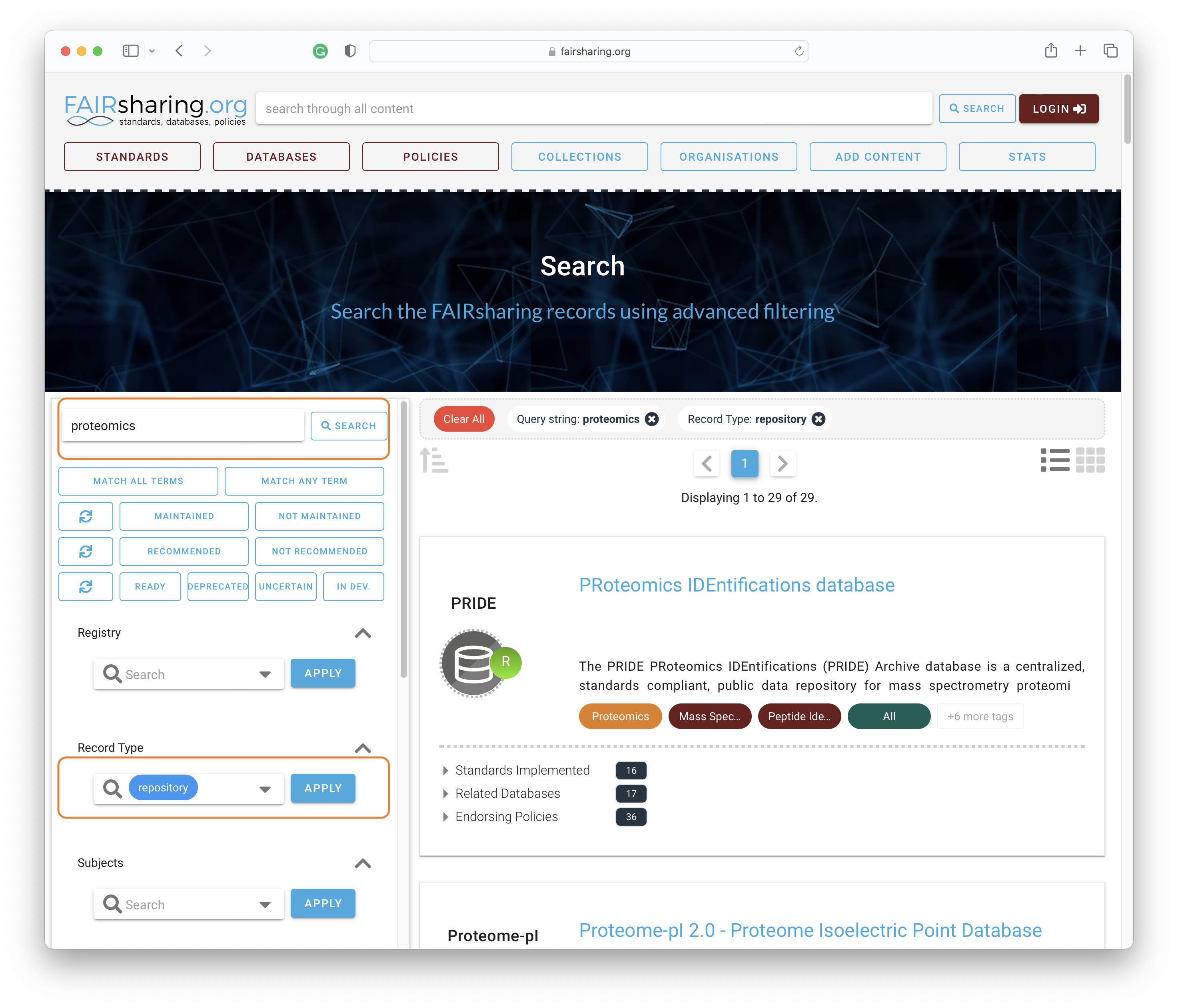
Choosing the right data repository for your data FAIRsharing helps researchers identify suitable data repositories, standards and policies relating to their data. Use this resource to identify data repositories for proteomic data.
Solution
Access the search bar for the FAIRsharing database registry. Search for proteomics and select “repository” under “Record Type”.
Useful Resources
- Registries and lists of public repositories: FAIR Cookbook and nature journal
- Publishing your data: RDMkit
- Using Bioschemas to embed metadata into webpages: FAIR Cookbook Bioschemas
Key Points
A good way to FAIRify your (meta)data is through submission to a public repository, if it indexes and exposes the appropriate level of metadata to serve your specific use case or serve your envisaged users
Use Repositories that support controlled access to data if necessary
FAIRsharing is a useful resource to locate relevant public repositories